

Wypróbuj Weglot za darmo




Wielu użytkowników Weglot chce mieć pewność, że wszystkie adresy URL ich stron internetowych są dokładnie przetłumaczone(po pierwszej warstwie tłumaczenia maszynowego podanej przez Weglot). Dla wielu, jeśli posiadasz dużą stronę internetową, przetłumaczoną na wiele języków, może to być czasochłonne.
Zauważyliśmy również dzięki opiniom naszych użytkowników, że niektórzy z nich byli nieco zdezorientowani, gdy rozpoczynali swój pierwszy projekt tłumaczenia strony internetowej. Często zastanawiali się, dlaczego na liście tłumaczeń widzą tylko adres URL swojej strony głównej, a nie wszystkich innych stron, lub jak wygenerować tłumaczenia ich treści.
Wiedzieliśmy więc, że w tym obszarze jest miejsce na poprawę. Mogliśmy pomóc naszym użytkownikom łatwiej wejść na pokład i zarządzać ich projektami szybciej i wydajniej, ale jedyną rzeczą było to, że nie mieliśmy jeszcze rozwiązania.
Jak można się już domyślić... doprowadziło to do wydania funkcji Manage URLs, pozwalającej użytkownikowi na skanowanie adresów URL swojej strony internetowej i generowanie przetłumaczonych treści z Weglot Dashboard, szybko i sprawnie.
Niedawno funkcja ta została przeniesiona z listy tłumaczeń na nową stronę zarządzania tłumaczeniami według adresów URL, gdzie stała się jeszcze bardziej elastyczna i potężna, więc pomyśleliśmy, że nadszedł czas, aby opowiedzieć, jak ta funkcja została wprowadzona w życie.
Na początku 2020 roku lockdown spowodowany pandemią dał mi w końcu możliwość zajęcia się nauką języka programowania Golang, którą musiałem odkładać z powodu braku czasu.
Golang (lub w skrócie Go) to język stworzony przez Google, który zyskuje na popularności w ciągu ostatnich kilku lat.

Jest to statycznie kompilowany język programowania, który został zaprojektowany, aby pomóc programistom w pisaniu szybkiego, solidnego i współbieżnego kodu. Jego prostota pozwala na pisanie i utrzymywanie dużych i złożonych programów bez poświęcania wydajności: Golang może być postrzegany jako nieoczekiwane dziecko Pythona i C: (dość) łatwy do napisania i szybki w działaniu.
Moim zdaniem najlepszym sposobem na nauczenie się nowego języka programowania (lub nowego frameworka lub czegokolwiek innego) jest znalezienie dobrego projektu, w którym można zastosować to, czego się nauczyłeś. Nie jest to najłatwiejsze zadanie: jeśli deweloperzy to czytają, wiedzą , jak trudne może to być.
Dobry projekt poboczny musi spełniać pewne wymagania:
Dlaczego więc o tym wspominam? Kiedy zastanawiałem się nad tym, co mogłoby być świetnym projektem pobocznym do rozpoczęcia nauki Golanga, przyszło mi do głowy, że web crawler mógłby idealnie pasować do powyższego opisu, a także mógłby rozwiązać niektóre z problemów, które chcieliśmy naprawić dla użytkowników Weglot .
Zastanówmy się, crawler internetowy (często nazywany "botem") to, w najprostszej formie, program stworzony do odwiedzania strony internetowej i pozyskiwania informacji.
Jednym z typowych przypadków użycia crawlera internetowego może być wykrycie i odwiedzenie każdej strony witryny internetowej, a następnie wygenerowanie mapy witryny. Lub indeksowanie jej zawartości, na przykład przez boty Google.
W naszym przypadku potrzebowaliśmy czegoś, czego nasi użytkownicy mogliby użyć do skanowania swojej witryny i importowania z powrotem wszystkich adresów URL swojej witryny.
Szukaliśmy również nowego sposobu generowania tłumaczeń. Uwaga dodatkowa dla tych, którzy nie są zaznajomieni z Weglot... "generowanie tłumaczeń" oznacza, że adresy URL (i treści w nich zawarte) pojawiają się na liście tłumaczeń Weglot , umożliwiając ręczną edycję tłumaczeń.
W tym momencie użytkownicy musieli odwiedzić ich stronę internetową w przetłumaczonym języku, aby je wygenerować. Działa to naprawdę dobrze, gdy witryna ma tylko kilka stron i nie ma wielu przetłumaczonych języków, ale może szybko stać się przytłaczającym zadaniem, jeśli posiadasz bardzo dużą witrynę z tysiącami stron.
Pomysł wykorzystania web crawlera do zautomatyzowania tego zadania szybko zaczął wydawać się idealnym rozwiązaniem i byłby to idealny przypadek użycia funkcji programowania współbieżnego Golang!
Tak więc w styczniu 2020 roku zacząłem prototypować crawlera internetowego, ucząc się podstaw Golanga i wkrótce miałem coś, co mogłem pokazać Rémy'emu, CTO Weglot.
Nie było to wiele, prosty program, który pobierał adres URL jako dane wejściowe i rozpoczynał indeksowanie strony internetowej, odwiedzając każdy link do tej samej domeny, który znalazł, ale był szybki i skuteczny.
Po szybkiej demonstracji Rémy był podekscytowany dostarczonym rozwiązaniem i poświęcił czas potrzebny na badania i rozwój, aby sfinalizować POC (proof of concept), a następnie zastanowić się, w jaki sposób moglibyśmy hostować rozwiązanie do przyszłego wykorzystania produkcyjnego.
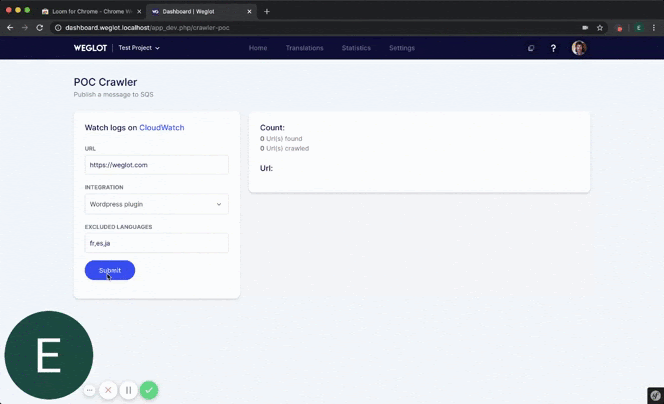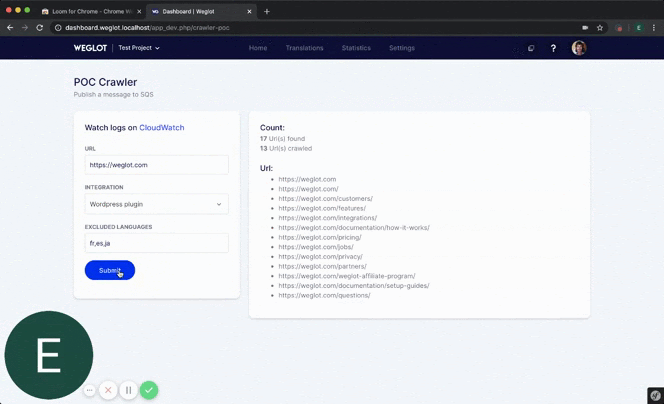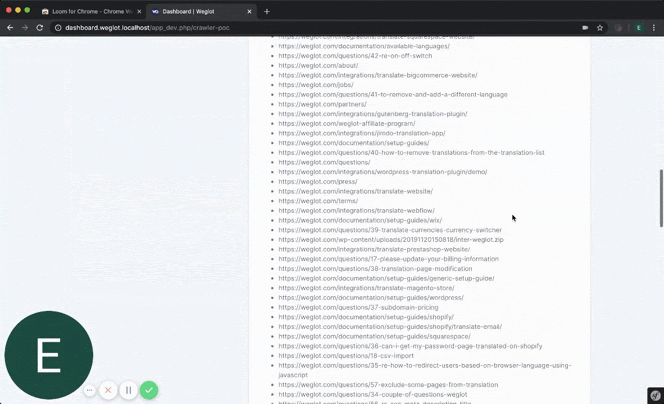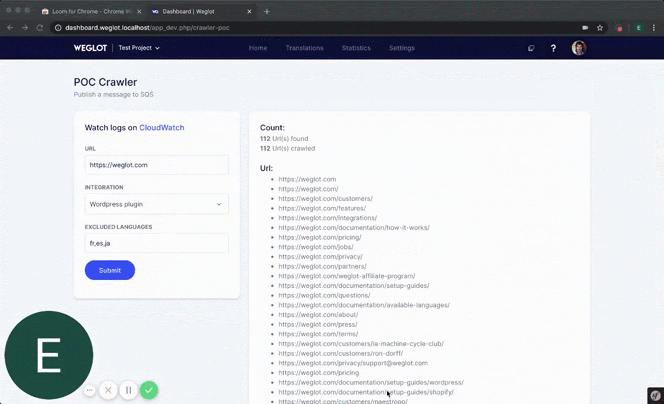
Jako inżynier oprogramowania, to naprawdę wspaniałe uczucie, gdy pracujesz nad czymś samodzielnie, a następnie dostajesz czas na pełne rozwinięcie swojego produktu. To wspaniałe uczucie uznania, które motywowało mnie przez cały czas, aż do uzyskania produktu gotowego do produkcji(co było jeszcze długą drogą).
Oprócz ukończenia bota, który wciąż potrzebował funkcji generowania treści i dodatkowej pracy, aby uwzględnić różnice między różnymi systemami CMS i integracjami, zacząłem myśleć o tym, jak moglibyśmy hostować i udostępniać bota naszym użytkownikom.
Moją pierwszą myślą było użycie klasycznego i sprawdzonego rozwiązania: uruchomienie instancji obliczeniowej na AWS i wystawienie bota za serwerem WWW. Wydawało się to dobrym pomysłem, ale im więcej o tym myślałem, tym bardziej obawiałem się kilku kwestii.
Po pierwsze, nie miałem pojęcia o obciążeniu serwera i liczbie użytkowników korzystających z tej funkcji w tym samym czasie. Co, jeśli udostępniona pojemność jest wystarczająca, ale nagle masz wielu użytkowników indeksujących różne bardzo duże witryny jednocześnie?
Ponieważ nie miałem wcześniejszego doświadczenia w hostowaniu programu Go, trudno było określić, jakie zasoby (procesor, pamięć RAM...) będą wystarczające, aby zapewnić użytkownikom doskonałe wrażenia.
Ponadto czułem, że klasyczny serwer sieciowy "zawsze włączony" nie jest najbardziej wydajnym rozwiązaniem. Ludzie nie będą indeksować ich witryny przez cały czas: po zaimportowaniu adresów URL i wygenerowaniu treści nie powinieneś codziennie korzystać z bota, nawet jeśli często publikujesz nowe / zaktualizowane treści.
Myśląc o tym, zaczęło to wyglądać jak idealny przypadek użycia dla hostingu bezserwerowego.
Dla tych, którzy przegapili trend serverless kilka lat temu, szybko podsumuję, jak to działa:
Ten model hostingu ma 2 główne zalety:
Pamiętasz, jak mówiłem, że trudno jest przewidzieć, jakich zasobów będzie potrzebował serwer do uruchomienia bota? Cóż, teraz nie musisz się tym przejmować, dla każdego żądania tworzony jest nowy bezstanowy izolowany kontener, aby uruchomić w nim swój kod, nie ma ryzyka przekroczenia pojemności serwera, każde żądanie otrzymuje własny kontener do uruchomienia.
A więc wszystko jest najlepsze w najlepszym z możliwych światów? No prawie!
W 2020 r. przetwarzanie bezserwerowe było ograniczone do 5 minut (przynajmniej w przypadku AWS, nie mam doświadczenia z hostingiem bezserwerowym na Google Cloud Platform lub Microsoft Azure). Ma to sens, ponieważ ten model hostingu został zaprojektowany do krótkich zadań, takich jak generowanie plików PDF lub przycinanie obrazów.
W naszym przypadku 5 minut było jednak trudnym problemem. Chociaż jest to więcej niż wystarczające do indeksowania małej, szybko reagującej strony internetowej, z pewnością osiągnęłoby limit przed zakończeniem zadania dla dużych witryn e-commerce, które mogą z łatwością zawierać dziesiątki tysięcy stron i czasami reagują nieco wolniej.
Już miałem zrezygnować z serverless, gdy na początku 2020 roku AWS ogłosił, że zwiększy limit 5 minut do 15 minut!
Niestety, jak to często bywa w przypadku AWS, nie zapewniają oni zbyt wielu informacji na temat nowych funkcji, gdy je ogłaszają, limit czasu został przedłużony, ale nie było żadnych wyjaśnień, jak go uzyskać.
Oszczędzę ci wielu prób i błędów oraz badań, które przeprowadziłem, aby znaleźć sposób na przedłużenie limitu do 15 minut, ale zapewniam, że nie było to łatwe 🙂
Limit 5 minut był w rzeczywistości limitem egzekwowanym na poziomie infrastruktury, AWS nie utrzyma połączenia HTTP dłużej niż 5 minut między różnymi usługami, rozwiązaniem było po prostu nie wyzwalanie kodu bezserwerowego za pomocą wywołania HTTP, istnieje wiele innych sposobów, w naszym przypadku skonfigurowaliśmy wyzwalanie za pomocą SQS: usługi kolejkowania wiadomości AWS.
Gdy problem z hostingiem został rozwiązany, pozostało jeszcze jedno zadanie do wykonania, zanim mogliśmy zakończyć dzień.
Do tej pory mieliśmy działającego bota, hostowanego w skalowalny i opłacalny sposób, ostatnią rzeczą, jakiej potrzebowaliśmy, było wysyłanie danych generowanych przez bota z powrotem do użytkowników.
Ponieważ chciałem, aby funkcja była jak najbardziej interaktywna, zdecydowałem się na komunikację w czasie rzeczywistym między botem a pulpitem nawigacyjnym Weglot .
Czas rzeczywisty nie jest obowiązkowy w przypadku tego rodzaju funkcji, zawsze można zadowolić się prostszym rozwiązaniem, takim jak długie ankietowanie, ale chciałem mieć pewność, że nasi użytkownicy otrzymają informację zwrotną, gdy tylko crawler rozpocznie swoją pracę, i bądźmy szczerzy, był to również sposób, aby pozwolić botowi zabłysnąć i pokazać jego potencjał 🙂
Ponieważ nie mieliśmy wtedy nic do obsługi komunikacji w czasie rzeczywistym (nie mieliśmy do tego żadnego zastosowania), zdecydowaliśmy się na sprawdzone rozwiązanie, napisaliśmy prosty serwer websocket w nodejs i hostowaliśmy go na instancji EC2 AWS.
Po pewnych pracach nad botem w celu zaimplementowania komunikacji z serwerem websocket i zautomatyzowania wdrażania, byliśmy w końcu gotowi przejść do testowania przed wydaniem na produkcję.

To, co zaczęło się jako projekt poboczny, ostatecznie trafiło na deskę rozdzielczą.
Świetnie się bawiłem pisząc crawlera i rozwiązując liczne napotkane problemy. Przy okazji wiele się nauczyłem: nowego języka programowania i nowych umiejętności w ekosystemie AWS.
Go jest zdecydowanie językiem, którego będę używał ponownie, naprawdę błyszczy w zadaniach sieciowych i programowaniu kooperacyjnym. Jest to również bardzo dobry język do parowania z przetwarzaniem bezserwerowym ze względu na niski ślad pamięciowy w porównaniu do języków takich jak Js, PHP czy Python.
Ponieważ bot otworzył przed nami nowe perspektywy, mamy pewne plany na przyszłość. Planujemy przepisać nasze narzędzie do liczenia słów, aby było bardziej wydajne i wydajne, możemy również użyć go do rozgrzania pamięci podręcznej (zapełnienia jej danymi).
Mam nadzieję, że to spojrzenie na technologię Weglotspodobało ci się tak bardzo, jak mi podobało się pisanie tego artykułu, nie krępuj się wypróbować bota dla siebie!

Zapewnimy obsługę Twoich języków źródłowych w czasie rzeczywistym. To Ty decydujesz, jak daleko chcesz się posunąć. Wypróbuj Weglot darmo już dziś.
Cieszy się zaufaniem ponad 70 000 marek z całego świata







Zacznij za darmo i uruchom wielojęzyczną stronę internetową w ciągu kilku minut.



Od 2016 roku Weglot zaufaniem marek na całym świecie, które przetestowały tę platformę. Dołącz do nich już dziś.




Najlepszym sposobem, aby zrozumieć potęgę Weglot wypróbowanie go samodzielnie. Wypróbuj go za darmo i bez żadnych zobowiązań.
Jeśli nie jesteś jeszcze gotowy, aby połączyć swoją stronę internetową, w panelu administracyjnym dostępna jest strona demonstracyjna.
