

Try Weglot for free




Many Weglot users like to ensure all the URLs of their website are accurately translated (after the first layer of machine translation given by Weglot). For many, if you own a large website, translated into many languages, it can be time-consuming.
We also noticed through feedback from our users that some of them were a bit confused when starting their first website translation project. They would often wonder why they could only see their homepage URL in the translation list and not all the other pages, or how to generate the translations of their content.
So, we knew there was room for improvement in this area. We could help our users on board more easily and manage their projects faster and more efficiently, but the only thing was, we didn’t have a solution yet.
As you may have already guessed…this led to the release of the Manage URLs feature, allowing the user to scan the URLs of their website and to generate their translated content from the Weglot Dashboard, fast and efficiently.
Recently, this feature has been moved from the Translation List to the new translation management by URL page where it has been made even more flexible and powerful, so we thought it was high time to tell you how this feature was brought to life.
At the beginning of 2020, the lockdown due to the pandemic finally gave me the opportunity to tackle learning the programming language Golang that I had to postpone due to lack of time.
Golang (or Go for short) is a language made by Google which is gaining a lot of traction these past few years.

It’s a statically compiled programming language that was designed to help developers write fast, robust, and concurrent code. Its simplicity allows for writing and maintaining large and complex programs without sacrificing performance: Golang can be seen as the unexpected child of Python and C: (quite) easy to write and fast to perform.
In my opinion, the best way to learn a new programming language (or a new framework or whatever) is to find a good project to put what you learn into practice. It’s not the easiest task: if developers are reading this, they know how hard it can be.
A good side project must meet some specifications:
So why am I mentioning this? As I was thinking about what could be a great side project to start learning Golang, it occurred to me that a web crawler could perfectly fit the above description and could also solve some of the issues we were looking to fix for Weglot users.
Let’s think about it, a web crawler (often named ‘bot’) is, in its simplest form, a program made to visit a website and extract information.
One typical use case of a web crawler could be to discover and visit every page of a website and then generate a sitemap. Or index its content, think Google bots for example.
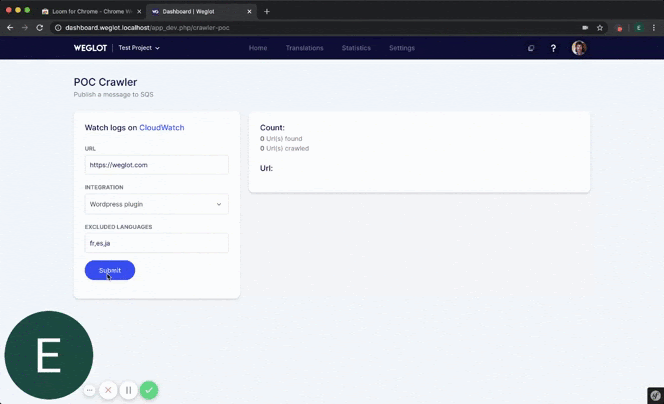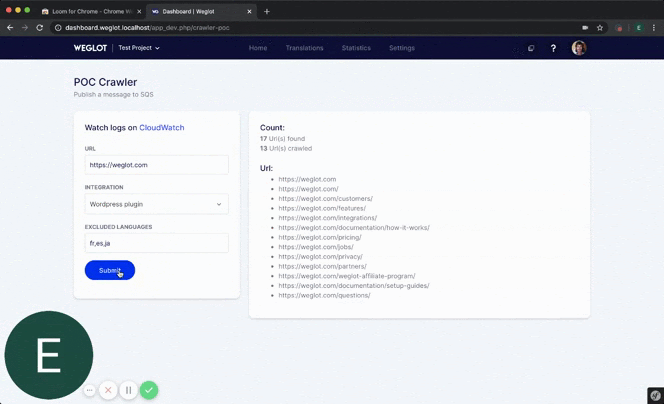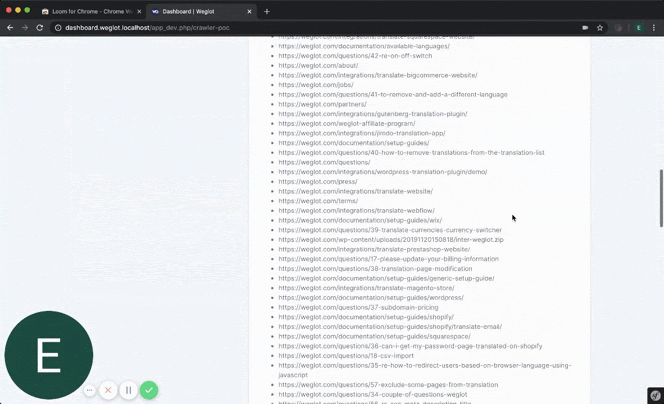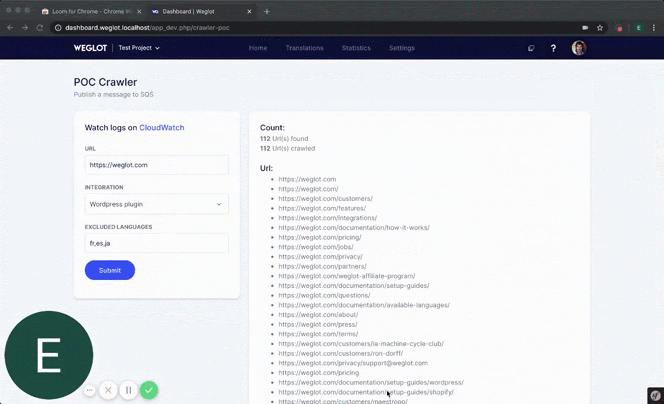
In our case, we needed something our users could use to scan their website and import back all the URLs of their site.
We were also looking for a new way to generate translations. Side note for those not familiar with Weglot…‘generating translations’ means your URLs (and the content inside them) appear in your Weglot translations list, enabling you to make manual edits to the translations.
At that point, users had to visit their website in a translated language to generate them. It works really well when your website only has a few pages and you don’t have many translated languages but can quickly become an overwhelming task if you own a very large website with thousands of pages.
The idea of using a web crawler to automate this task rapidly started to look like an ideal solution and it would be a perfect use case for Golang concurrent programming features!
So in January 2020, I started prototyping a web crawler while learning the basics of Golang and soon enough I had something I could show to Rémy, Weglot’s CTO.
It wasn’t much, a simple program that would take a URL as an input and would start crawling the website, visiting every same domain link it would find, but it was fast and efficient.
After a quick demonstration, Rémy was excited about the solution provided and to take the time needed for research and development to finalize the POC (proof of concept) and then think about how we could host the solution for future production usage.
As a software engineer, it feels really great when you work on something on your own and then get granted time to fully develop your product. It’s a great feeling of acknowledgment and it would motivate me all the way until we had a production-ready product (which was still a long way to go).
Alongside finishing the bot, which still needed the generate content feature and some additional work to take into account differences between different CMS and integrations, I started to think about how we could host and expose the bot to our users.
My first thought was to use the classic and well-proven solution: spinning a compute instance on AWS and exposing the bot behind a web server. It seemed like a good idea but the more I thought about it, the more I was concerned about several issues.
First, I had no idea about the charge the server would have to take and how many users would use the feature at the same time. What if the provisioned capacity is enough but you suddenly have many users crawling different very large websites at once?
As I had no prior experience with hosting a Go program, it was hard to determine what resources (CPU, RAM…) would be enough to provide a great user experience.
Additionally, I felt like the classic ‘always up’ web server was not the most efficient solution. People wouldn’t be crawling their website all the time: once you imported your URLs and generated your content, you’re not supposed to use the bot on a daily basis even if you often publish new/updated content.
Thinking about it, it started to look like a perfect use case for serverless hosting.
For those who missed the serverless trend a few years ago, I’ll quickly sum up how it works:
This hosting model immediately comes with 2 main advantages:
Remember when I said that it was hard to anticipate what resources a server would need to run the bot? Well, you don’t have to bother with this now, for every request a new stateless isolated container is created to run your code inside it, there’s no risk of exceeding the server’s capacity, every request gets its own container to run in.
So, everything is for the best in the best of all possible worlds? Well almost!
Back in 2020, serverless computing was limited to 5 minutes, (at least for AWS, I have no experience with serverless hosting on Google Cloud Platform or Microsoft Azure). It makes perfect sense as this hosting model was designed for short tasks like generating a pdf or cropping images for example.
In our case though, the 5-minute duration was a tough problem. Whilst it’s more than enough to crawl a small, fast-responding website, it would most certainly hit the limit before completing the task for large ecommerce websites which can easily have tens of thousands of pages and are sometimes a bit slow to respond.
I was just about to give up on serverless when AWS made an announcement in early 2020 – they would increase the 5 minutes limit to 15 minutes!
Unfortunately, as it’s often the case with AWS, they don’t provide much insight about new features when they announce them, the time limit was extended but there were no explanations on how to get it.
I’ll save you the many trial and errors and research I did to find how to extend the limit to 15 minutes but let me assure you it wasn’t easy 🙂
The 5 minutes limit was actually a limit enforced at the infrastructure level, AWS won’t maintain an HTTP connection more than 5 minutes between its different services, the solution was to simply not trigger the serverless code with an HTTP call, there are many other ways, in our case we set up for a triggering with SQS: the AWS message queuing service.
Once the hosting problem was sorted out, there was one more task to complete before we could call it a day.
So far we had a working bot, hosted in a scalable and cost-efficient way, the last thing we needed was to send the data produced by the bot back to the users.
Since I wanted the feature to be the most interactive as possible, I opted for real-time communications between the bot and the Weglot dashboard.
Real-time isn’t mandatory for this kind of feature, you can always settle for a simpler solution like long polling but I wanted to make sure our users would receive feedback as soon as the crawler had started its job, and let’s be honest, it was also a way to let the bot shine and show its potential 🙂
As we didn’t have anything to handle real-time communications back then (we had no use for it) we decided to go for a proven solution, we wrote a simple websocket server in nodejs and hosted it on an EC2 AWS instance.
After some work on the bot to implement the communication with the websocket server and to automate the deployment, we were finally ready to move on testing before releasing to production.

What started as a side project eventually made its way into the dashboard.
I had a lot of fun writing the crawler and solving the numerous problems I encountered. In the end, I also learned a lot: a new programming language and new skills in the AWS ecosystem.
Go is definitely a language I’ll use again, it really shines for networking tasks and cooperative programming. It’s also a very good language to pair with serverless computing due to its low memory footprint compared to languages such as Js, PHP or Python.
As the bot opened up new perspectives for us, we have some plans for the future. We’re planning to rewrite our wordcount tool to make it more efficient and performant, we could also use it to warm up cache (populate it with data).
I hope you enjoyed this peek into Weglot’s tech as much as I enjoyed writing this article, feel free to try out the bot for yourself!

We’ll get your first languages live. You decide how far you want to go. Try Weglot for free today.
Trusted by 70,000+ global brands







Get started for free and have a multilingual website up and running in minutes.



Weglot is tested and trusted by brands worldwide since 2016. Join them today.




The best way to understand the power of Weglot is to see it for yourself. Test it for free and without any engagement.
A demo website is available in your dashboard if you’re not ready to connect your website yet.
